

Themengebiete WS25/26
Einleitung:
Im kooperativen Multi-Agenten Reinforcement Learning (MARL) versucht eine Vielzahl sogenannter Agenten – beispielsweise Roboter – durch Interaktion mit ihrer Umgebung gemeinsam ein Ziel zu erreichen, das für einen einzelnen Agenten in der Regel nicht erreichbar wäre. Üblicherweise erlernt dabei jeder Agent in einer Lernphase eine eigene Policy, also eine Handlungsstrategie, gegeben Informationen aus der Umgebung und dem Verhalten anderer Agenten.
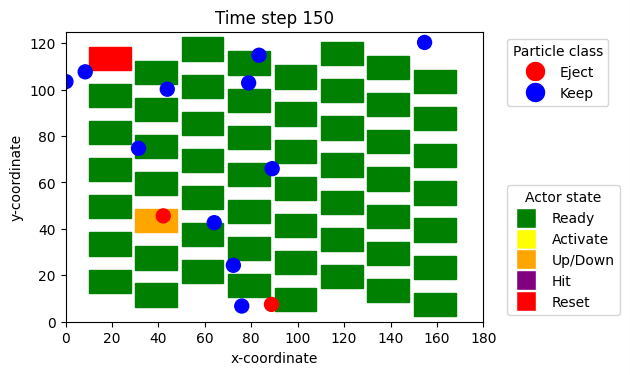
Im Rahmen dieses Praktikums soll zunächst ein bestehendes Open-Source-Paket für kooperatives MARL auf beispielhafte Benchmark-Umgebungen angewendet werden. In einer zweiten Phase soll die Steuerung eines sogenannten Multi-Aktoren-Array Sortierers mittels MARL erlernt werden. Dieser Sortierer besteht aus mehreren Reihen mechanischer Aktoren, wobei jeder Aktor als eigenständiger Agent betrachtet werden kann. Dadurch ergeben sich zahlreiche Möglichkeiten zur Trennung von Partikeln. Ziel ist es, eine Konfiguration zu identifizieren, die hinsichtlich der Sortiergenauigkeit – gemessen an der Anzahl korrekt ausgeschleuster und korrekt nicht-ausgeschleuster Partikel – optimal ist.
Aufgaben:
- Einarbeitung in MARL und entsprechende Softwarepakete
- Aufsetzen eines Softwarepakets und Lernen auf kooperativen Beispielumgebungen
- Implementierung eines Simulationsmodell des Multi-Aktoren-Array Sortierers als Umgebung für MARL
- Lernen, Evaluation und iterative Verbesserung des MARL-Modells und der Umgebung
Voraussetzungen:
- Grundkenntnisse in Python
- Grundkenntnisse in Reinforcement Learning
Projekt 2 - Labyrinth Geschicklichkeitsspiel mit modellbasiertem Deep Reinforcement Learning
- Ansprechperson:
Einleitung:
Deep Reinforcement Learning ermöglicht das kontinuierliche, automatische Lernen eines Reglers für beliebige Aufgaben, so auch ein Labyrinth-Geschicklichkeitsspiel. Ein solches Echtzeitsystem wurde von einer Gruppe an der ETH Zürich entworfen und im letzten Praktikum am ISAS nachgebaut. Nun soll es verbessert und erweitert werden.
Aufgaben:
- Nachbau mit zuverlässigerer Mechanik
- Wiederverwendbare Systeminstallation in Docker rootless
- Einfluss der Netz-Architektur evaluieren
- Modifikationen: Abkürzungen nehmen lassen, eigenes Labyrinth ohne Bande, Bande nicht berühren…
Voraussetzungen:
- Erfahrung mit Programmieren
- bevorzugt: Erfahrung mit ROS
Literatur:
- https://www.cyberrunner.ai/
- Thomas Bi, Raffaello D’Andrea, Sample-Efficient Learning to Solve a Real-World Labyrinth Game Using Data-Augmented Model-Based Reinforcement Learning

Einleitung:
Die Lokalisierung anhand von Signallaufzeiten elektromagnetischer Signale ist weit verbreitet, etwa in der Multilateration oder bei GNSS. Leider kann die exakte Lösung des entsprechenden Least-Squares-Problems nicht in geschlossener Form berechnet werden, sondern es handelt sich um ein nichtlineares Optimierungsproblem nach drei Orts- und einer Zeitvariablen. In diesem Praktikum sollen GNSS-Rohdaten aller sichtbaren Satelliten gesammelt und daran verschiedene Lösungsalgorithmen verglichen werden, darunter ein neu am ISAS entwickelter, der vor allem bei vielen Messungen gleichzeitig einen Geschwindigkeitsvorteil bietet.
Aufgaben:
- Recherche um an die GPS-Rohdaten zu kommen
- Möglichkeit 1: Auswahl, Bestellung und Inbetriebnahme geeigneter Empfänger
- Möglichkeit 2: via Android-App
- Implementierung und Geschwindigkeitsvergleich gängiger Lösungsalgorithmen auf dem PC
Voraussetzungen:
- Erfahrung mit Programmieren
- bevorzugt: Erfahrung mit Android-Programmierung
Literatur:
- Daniel Frisch 2025, Why you Shouldn’t Use TDOA for Multilateration
- https://developer.android.com/develop/sensors-and-location/sensors/gnss

Einleitung:
LLMs sind zu recht beeindruckenden Interaktionen in der Lage, man stößt aber auch sehr schnell an Grenzen, sodass sie oftmals doch nicht wirklich Arbeit abnehmen können. Das Verhalten lässt sich durch sogenanntes „fine-tuning“ verbessern. Dabei wird das vortrainierte Netz mit für den jeweiligen Nutzer relevanten Daten weitertrainiert. Dadurch wird es zwar in manchen Wissensgebieten schlechter, aber auf dem relevanten Gebiet besser.
Aufgaben:
- Recherche: Welche vortrainierten Netze kommen infrage?
- Sammlung relevanten öffentlichen Daten: ISAS-Publikationen, oft zitierte Literatur, …
- Private Daten, Datenschutz eruieren: vergangene Praktikumsberichte, interne Dokumente, …
- Nachtrainieren eines oder mehrerer LLMs
- Evaluation: wie gut kann es z.B. einen Praktikumsbericht schreiben?
Voraussetzungen:
- Erfahrung mit Programmieren
- bevorzugt: Erfahrung mit Python
Literatur:
- Wozniak 2024, Personalized Large Language Models

Einleitung:
In sicherheitsrelevanten Bereichen gibt es großen Bedarf an echten Zufallszahlen. Diese lassen sich mit den üblichen deterministischen Computerarchitekturen nicht ohne weiteres generieren, sondern man benötigt dedizierte Hardware, um auf den entsprechenden physikalischen Prozess zugreifen zu können. In diesem Praktikum soll das quantenbasierte Schrotrauschen der Zenerdiode digitalisiert und an den PC übertragen werden. Beispielsweise in Form eines USB-Sticks, der sich als Tastatur anmeldet – auf diese Weise muss kein dedizierter Treiber geschrieben werden. Diese sollen übrigens später in der Vorlesung „Sampling Methods for Machine Learning“ zum Einsatz kommen.
Aufgaben:
- Recherche: Digitalisierung von Schrotrauschen
- Aufbau und Test einer elektronischen Schaltung
- Design und Bestellen einer Platine
Voraussetzungen:
- Erfahrung mit elektronischen Schaltungen
- bevorzugt: Erfahrung USB-Schnittstelle
Literatur:
- Herrero-Collantes 2017, Quantum random number generators
Einleitung:
Die Interaktion mit entfernten und virtuellen Umgebungen ist ein zentrales Ziel moderner Telepräsenzsysteme. Für die visuelle Darstellung ermöglichen aktuelle Verfahren wie 3D Gaussian Splatting [1] bereits die fotorealistische Rekonstruktion von 3D-Szenen aus 2D-Bildern. Für Anwendungen in der Robotik oder in der haptischen Interaktion reicht eine rein visuelle Repräsentation jedoch nicht aus – hier werden Modelle benötigt, die physische Eigenschaften in Echtzeit abbilden können. Während sich für einzelne Objekte oft 3D-Mesh-Modelle eignen, sind diese für komplexe Umgebungen in der Regel zu speicherintensiv. Daher setzen viele robotische Systeme heute auf probabilistisches 3D-Mapping, z.B. in Form von OctoMap [2], das eine effiziente und skalierbare Umgebungskartierung erlaubt.
Ziel dieses Praktikums ist es, bestehende Technologien des 3D-Mappings zu analysieren und zu untersuchen, wie aus einfachen Bildern bzw. aus 3D Gaussian Splatting-Modellen eine probabilistische 3D-Karte erzeugt werden kann. Diese Karte soll anschließend in einem Algorithmus zur Kollisionserkennung innerhalb einer ROS-Umgebung eingesetzt werden. Darüber hinaus wird sie mit dem visuellen Modell, das auf denselben Eingabedaten basiert, verglichen.
Aufgaben:
- Strukturierte Recherche und Analyse der bestehenden Verfahren zu Probabilistic 3D-Mapping
- Einarbeitung in 3D Gaussian Splatting
- Entwicklung eines Verfahrens für die Erstellung einer probabilistischen 3D-Karte ausgehend von 2D-Kamerabildern
- Integration der 3D-Karte in einen Algorithmus zur Kollisionserkennung
- Vergleich von generierter 3D-Karte und visuellem Modell
Voraussetzungen:
- Kenntnisse in C++ und Python
- Grundkenntnisse in ROS (nicht zwingend notwendig)
- Unabhängiges Lernen und Arbeiten sowie Teamarbeit
Literatur:
- [1] Kerbl et al.: 3D Gaussian Splatting for Real-Time Radiance Field Rendering (https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/)
- [2] Hornung et al.: OctoMap: An Efficient Probabilistic 3D Mapping Framework Based on Octrees (https://octomap.github.io/)

Projekt 7 - Evaluierung von markerlosem Handtracking für die Kalibrierung einer haptischen Schnittstelle in VR
- Ansprechperson:
Einleitung:
Moderne Telepräsenz erweitert die visuelle Darstellung in VR-Anwendungen mit haptischen Interaktionen. Dafür kommen neben Head-Mounted-Displays (HMD) haptische Schnittstellen zum Einsatz. Eine wichtige Herausforderung dabei ist die Kalibrierung dieser beiden Komponenten miteinander, um die immersive visuelle Welt auf die reale haptische Komponente zu übertragen. Dafür wurde ein Kalibrierverfahren basierend auf dem HMD-Internen Hand-Tracking entwickelt.
Ziel dieses Praktikums ist die Evaluierung dieses Systems bestehend aus dem Handtracking des HMD, der Visualisierung in Unity und der raumgroßen haptischen Schnittstelle [1]. Basierend auf den Ergebnissen sollen Optimierungen des Kalibrierverfahrens entwickelt und getestet werden.
Bestehende Arbeiten befassen sich mit der Analyse der HMD-Internen Tracking-Systeme und wie sie für robuste Anwendungen transparent genutzt werden können [2, 3, 4]. Mit diesem Praktikum soll dieses System auf haptische Mensch-Maschinen-Interaktionen übertragen werden.
Aufgaben:
- Einarbeitung in bestehende Komponenten und verwandte Arbeiten
- Entwicklung von Evaluations-Metriken
- Durchführung und Auswertung von Experimenten
- Entwicklung und Test von Optimierungen hinsichtlich Genauigkeit und Bedienerfreundlichkeit
Voraussetzungen:
- Kenntnisse in C# (empfehlenswert)
- Grundkenntnisse in ROS und Unity (nicht zwingend notwendig)
- Unabhängiges Lernen und Arbeiten sowie Teamarbeit
Literatur:
- [1] M. Fennel et al.: HapticGiant: A Novel Very Large Kinesthetic Haptic Interface with Hierarchical Force Control
- [2] E. Godden et al.: Robotic Characterization of Markerless Hand-Tracking on Meta Quest Pro and Quest 3 Virtual Reality Headsets
- [3] M. Gmici et al.: Before hands disappear: Effect of early warning visual feedback method for hand tracking failures in virtual reality
- [4] D. Abdlkarim et al.: A methodological framework to assess the accuracy of virtual reality hand-tracking systems: A case study with the Meta Quest 2

Projekt 8 - Deterministisches Sampling in Python für moderne Machine-Learning-Anwendungen
- Ansprechperson:
Einleitung:
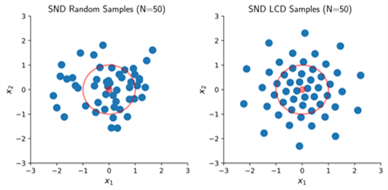
In modernen Machine-Learning-Anwendungen spielen Samples – etwa im Umgang mit stochastischen Modellen, Reinforcement-Learning-Policies oder Zustandsschätzungen – eine zentrale Rolle. Häufig werden zufällig generierte, normalverteilte Samples verwendet. Diese führen jedoch zu stark schwankenden Ergebnissen oder erfordern eine große Anzahl an Samples, um zuverlässige Resultate zu erzielen.
Als Alternative wurden Verfahren zur Erzeugung deterministischer Samples entwickelt, die Wahrscheinlichkeitsdichten mit einer festen Anzahl an Samples optimal approximieren können – wie im beigefügten Bild dargestellt. Insbesondere Normalverteilungen lassen sich so deutlich effizienter und reproduzierbar darstellen als mit zufälligen Samples.
Zurzeit existieren bereits C++-Funktionen sowie MATLAB-Skripte zur Generierung dieser deterministischen Samples. Da Machine-Learning-Anwendungen jedoch überwiegend in Python entwickelt werden, ist deren Nutzung mit erhöhtem Aufwand verbunden. Ziel dieses Praktikums ist daher die Entwicklung eines Python-Pakets, das die performanten C++-Funktionen über Bindings direkt in Python verfügbar macht.
Aufgaben:
- Integration bestehender C++-Funktionen in Python mittels Bindings
- Modularer Aufbau eines leicht installierbaren Python-Pakets unter Verwendung moderner Tools wie uv und ruff
- Implementierung automatisierter Tests mit GitHub CI/CD
- Erstellung von Anwendungsbeispielen, z. B. im Kontext der Zustandsschätzung
- Optional: Erweiterung des Samplings auf komplexere Wahrscheinlichkeitsdichten wie Gaußmischverteilungen
Voraussetzungen:
- Fortgeschrittene Kenntnisse in Python
- Von Vorteil: Erfahrung mit CMake und C++
- Von Vorteil: Erfahrung in der Entwicklung von Python-Paketen
Literatur:
- Steinbring, Jannik & Hanebeck, Uwe. (2014). LRKF revisited: The Smart Sampling Kalman Filter (S2KF). Journal of Advances in Information Fusion. 9. 106 – 123, (PDF) LRKF revisited: The Smart Sampling Kalman Filter (S2KF).
Einleitung:
Samples von Wahrscheinlichkeitsverteilungen haben eine Vielzahl an Anwendungsgebieten, unter anderem in der Zustandsschätzung und Regelung. Meist werden hier zufällig gezogene Samples verwendet, weil diese sehr einfach zu erzeugen sind. Sogenannte Quasi-Monte-Carlo Methoden verwenden stattdessen deterministische Samples, die meist schwieriger zu erzeugen sind, jedoch bei gleicher Anzahl Samples für bessere Ergebnisse sorgen als Zufallssamples.
Am ISAS wurde eine Methode entwickelt, mit der optimale deterministische Samples einer Gaußverteilung erzeugt werden können. Dazu wird ein Distanzmaß in einem Optimierungsverfahren minimiert. Da dies sehr aufwendig ist, kann diese Methode nur eingeschränkt verwendet werden, wenn die Laufzeit eine wichtige Rolle spielt.
In diesem Praktikum soll die Idee einer abgeschlossenen studentischen Arbeit fortgeführt werden, in der ein neuronales Netz trainiert wurde, um deterministische Samples zu erzeugen. Dieses Netz nutzt das gleiche Distanzmaß während des Trainings, wie das oben beschrieben Optimierungsverfahren, kann jedoch nach dem Training Samples deutlich schneller erzeugen.
Aufgaben:
- Einarbeitung in bestehende Python-Implementierung
- Literaturrecherche zu neuronalen Netzen für Punktsets
- Implementierung und Evaluation von Sampling einer Gaußverteilung mit einem neuronalen Netz
Voraussetzungen:
- Interesse am Training von neuronalen Netzen
- Von Vorteil: Erfahrung mit Python und PyTorch
- Selbstständige Arbeitsweise
Literatur:
- Hanebeck et. al: Dirac Mixture Approximation of Multivariate Gaussian Densities (2009)
Einleitung:
Optimal Control ist ein theoretischer Ansatz, in dem dynamische Systeme optimal im Hinblick auf eine festgelegte Kostenfunktion geregelt werden. Diese Kostenfunktion kann beispielsweise die Abweichung von einer gewünschten Ruhelage bestrafen. Optimal Control Probleme können unter anderem mit Methoden des Approximate Dynamic Programming (ADP) gelöst werden. Ein zentrales Konzept des ADP ist die Value Function, die angibt, wie „günstig“ ein bestimmter Zustand des Systems ist. Da die Value Function nur in Sonderfällen geschlossen berechnet werden kann, wird sie in der Praxis häufig angenähert. In diesem Praktikum soll die Approximation der Value Function mit einem Bayes‘schen neuronalen Netz (BNN) erfolgen. Diese Modelle haben den Vorteil, dass sie die Unsicherheit in ihren Prädiktionen quantifizieren, was mehrere Vorteile bietet. Durch die probabilistische Modellierung werden jedoch spezielle Trainingsverfahren notwendig. Als Beispielsystem soll eine virtuelle Umgebung aus der Softwarebibliothek „OpenAI Gymnasium“ dienen. Ziel des Praktikums ist es, das entwickelte Verfahren anzuwenden, um das System optimal zu steuern und die Wirksamkeit der Approximation der Value Function zu demonstrieren.
Aufgaben:
- Einarbeitung in Optimal Control, Dynamic Programming und BNNs
- Implementierung des Lern-Setups für die Value Function
- Implementierung des Regelungsalgorithmus
- Evaluation an einem Beispielsystem
Voraussetzungen:
- Interesse an Optimierung, Machine Learning und Theorie
- Gute Kenntnisse in Python
- Hohes Maß an Eigeninitiative
Literatur:
- Lawrence et. Al (2025), A view on learning robust goal-conditioned value functions: Interplay between RL and MPC
- Bertsektas & Tsitsiklis (1996), Neuro-Dynamic Programming, Kapitel 2
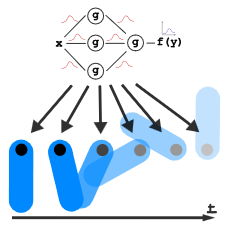
Projekt 11 - Heteroscedastic Gaussian Process Regression via Wasserstein Barycenters
- Ansprechperson:
Einleitung:
In many real-world problems, measurement noise is not constant but depends on the input. Standard Gaussian Processes often fail here, as they either over- or underestimate uncertainty across different regions. Heteroscedastic Gaussian Process Regression (HetGPR) addresses this by modeling input-dependent noise, but typically requires complex inference methods. Recent advances show that Wasserstein barycentric interpolation provides closed-form, geometrically meaningful interpolation between Gaussian distributions, simultaneously transporting means and covariances. This project explores combining HetGPR with Wasserstein barycenters to obtain a regression model that captures spatially varying noise while remaining efficient.
Aufgaben:
- Understand and implement a baseline HetGPR model.
- Implement Wasserstein barycentric interpolation for Gaussian distributions.
- Integrate interpolation into the GP framework for input-dependent noise modelling.
- Evaluate on benchmark datasets.
Voraussetzungen:
- Basic knowledge of Python or Julia
Literatur:
- K. Kersting et al., Most Likely Heteroscedastic Gaussian Process Regression, ICML 2007
- Q. Zhang et al., Improved Most Likely Heteroscedastic Gaussian Process Regression via Bayesian Residual Moment Estimator, IEEE TRANSACTIONS ONSIGNALPROCESSING 2020
- J. Zhou, U. Hanebeck, High-Quality Assumed Gaussian Filtering Based on Wasserstein Barycentric Interpolation, FUSION 2025
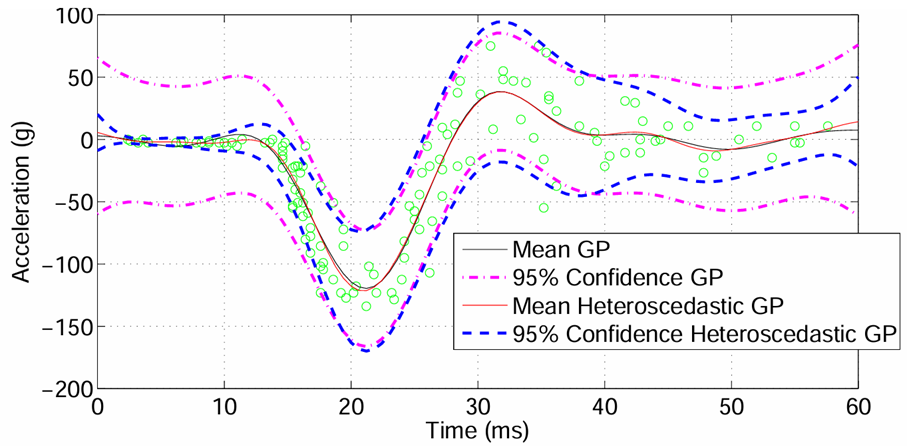
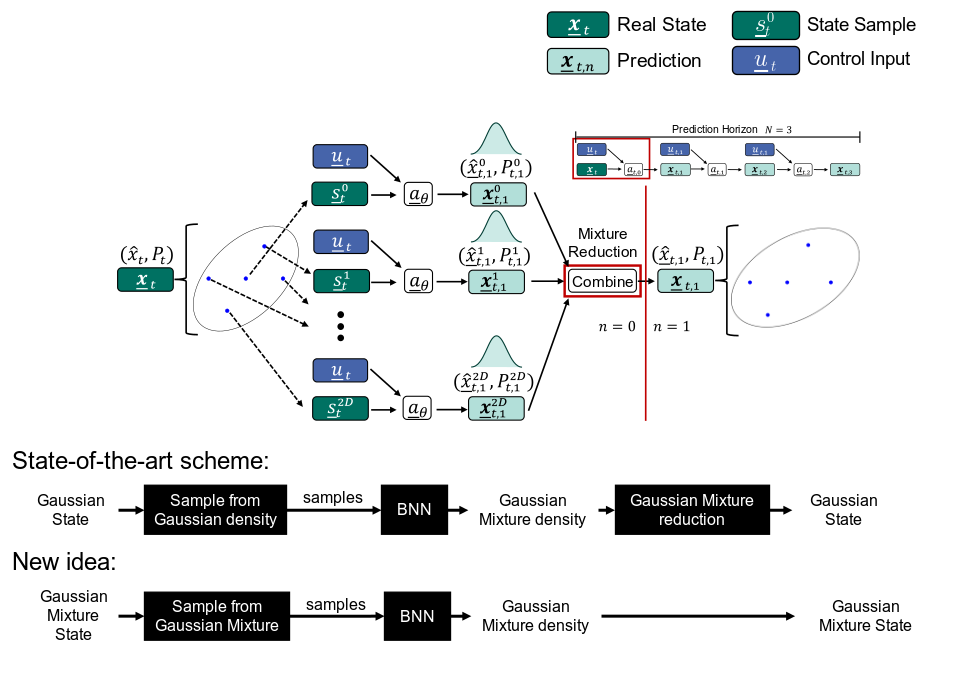
Projekt 12 - Deterministisches Sampling für Gaußmischverteilungen in der modellprädiktiven Regelung
- Ansprechperson:
Einleitung:
In der modellprädiktiven Regelung (MPC) werden optimale Steuergrößen berechnet, indem ausgehend vom aktuellen Systemzustand mögliche zukünftige Zustandsverläufe mithilfe eines Systemmodells simuliert werden. Da reale Modelle stets mit Unsicherheiten behaftet sind, ist es sinnvoll, diese explizit zu berücksichtigen – beispielsweise in Form von Wahrscheinlichkeitsdichten über die Zustände.
Modellunsicherheiten können durch datengetriebene Verfahren wie Bayes‘sche neuronale Netze (BNNs) erfasst werden. Diese liefern nach dem ersten Prädiktionsschritt typischerweise Gaußmischverteilungen als Ergebnis. Im Stand der Technik werden diese komplexen Dichten jedoch häufig vereinfacht und durch eine einzelne Normalverteilung approximiert, was zu Informationsverlust und unpräziseren Prädiktionen führt.
Im Rahmen dieses Praktikums soll keine solche Approximation vorgenommen werden. Stattdessen sollen aus den Gaußmischverteilungen deterministisch gezogene Samples verwendet werden, um die Prädiktion realistischer und effizienter zu gestalten. Ziel ist es, mit möglichst wenigen, aber gezielt gewählten Samples eine hohe Genauigkeit bei der Trajektorienvorhersage zu erreichen.
Aufgaben:
- Implementierung deterministischer Samplingverfahren für Gaußmischverteilungen in PyTorch
- Anwendung der generierten Samples zur Prädiktion von Zustandstrajektorien
- Evaluation der Qualität und Effizienz der Trajektorien
- Integration in die Modellprädiktive Regelung
- Optional: Integration von Filterschritten innerhalb des Prädiktionshorizonts zur Einbindung hypothetischer Messinformationen
Voraussetzungen:
- Fortgeschrittene Kenntnisse in Python
- Von Vorteil: Erfahrung mit PyTorch und probabilistischen Modellen
Literatur:
- X. Wu, E. Wedernikow and M. F. Huber, "Data-Efficient Uncertainty-Guided Model-Based Reinforcement Learning with Unscented Kalman Bayesian Neural Networks," 2024 American Control Conference (ACC), Toronto, ON, Canada, 2024, pp. 104-110, https://doi.org/10.23919/ACC60939.2024.10644690.
Einleitung:
Modellprädiktive Regelung (MPC, engl. model predictive control) ist eine Methode der Regelungstechnik, die auf der Modellierung des zu regelnden Systems basiert. Ziel ist es, durch die Vorhersage zukünftiger Systemzustände optimale Stellgrößen zu berechnen. Diese Technik findet Anwendung in verschiedenen Bereichen wie der Automobilindustrie und der Robotik. Das Projekt bietet eine spannende Gelegenheit, tief in die Theorie der MPC einzutauchen und praktische Erfahrungen mit verschiedenen Implementierungsbibliotheken zu sammeln.
Aufgaben:
- Einarbeitung in die Funktionsweise verschiedener Ansätze der modellprädiktiven Regelung
- Implementierung mit verschiedenen Bibliotheken wie PyTorch, Google JAX
- Evaluation bezüglich z. B. Güte, Geschwindigkeit, Einfachheit der Implementierung, Limitierungen
Voraussetzungen:
- Fortgeschrittene Kenntnisse in Python
- Bevorzugt: Erfahrung mit Differentialgleichungen, numerische Methoden / Optimierung
- Regelungstechnische Vorkenntnisse von Vorteil
Literatur:
- Diehl, M., Bock, H., Diedam, H., Wieber, PB. (2006). Fast Direct Multiple Shooting Algorithms for Optimal Robot Control. In: Diehl, M., Mombaur, K. (eds) Fast Motions in Biomechanics and Robotics. Lecture Notes in Control and Information Sciences, vol 340. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-36119-0_4
- G. Williams, P. Drews, B. Goldfain, J. M. Rehg and E. A. Theodorou, "Information-Theoretic Model Predictive Control: Theory and Applications to Autonomous Driving," in IEEE Transactions on Robotics, vol. 34, no. 6, pp. 1603-1622, Dec. 2018, https://doi.org/10.1109/TRO.2018.2865891